2020
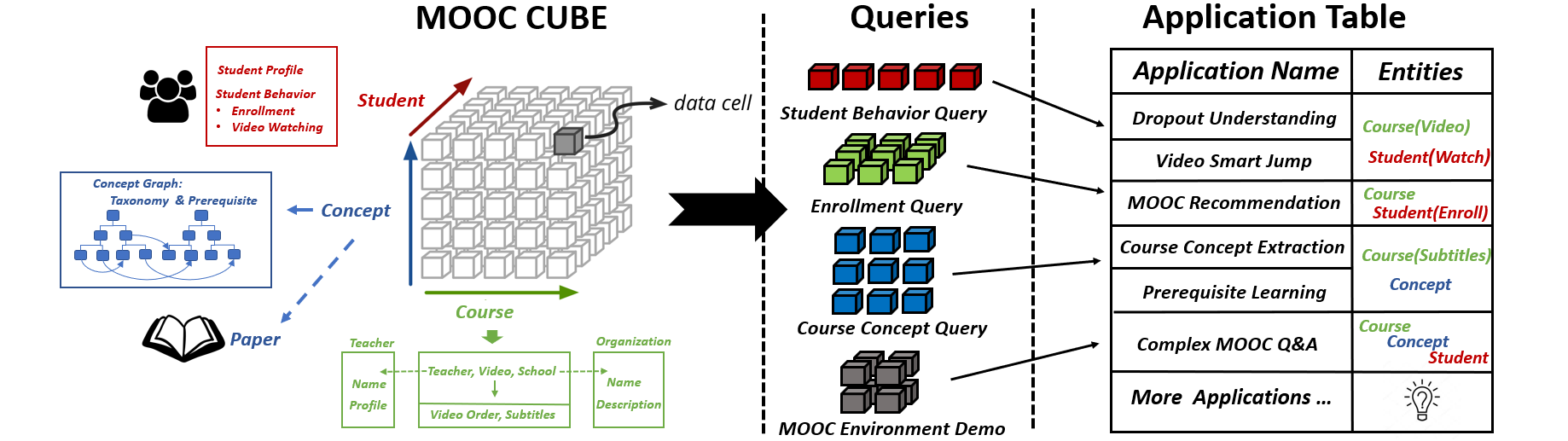
The prosperity of Massive Open Online Courses (MOOCs) provides fodder for many NLP and AI research for education applications, e.g., course concept extraction, prerequisite relation discovery, etc. However, the publicly available datasets of MOOC are limited in size with few types of data, which hinders advanced models and novel attempts in related topics. Therefore, we present MOOCCube, a large-scale data repository of over 700 MOOC courses, 100k concepts, 8 million student behaviors with external resource. Moreover, we conduct prerequisite discovery task as an example application to show the potential of MOOCCube in facilitating relevant research.
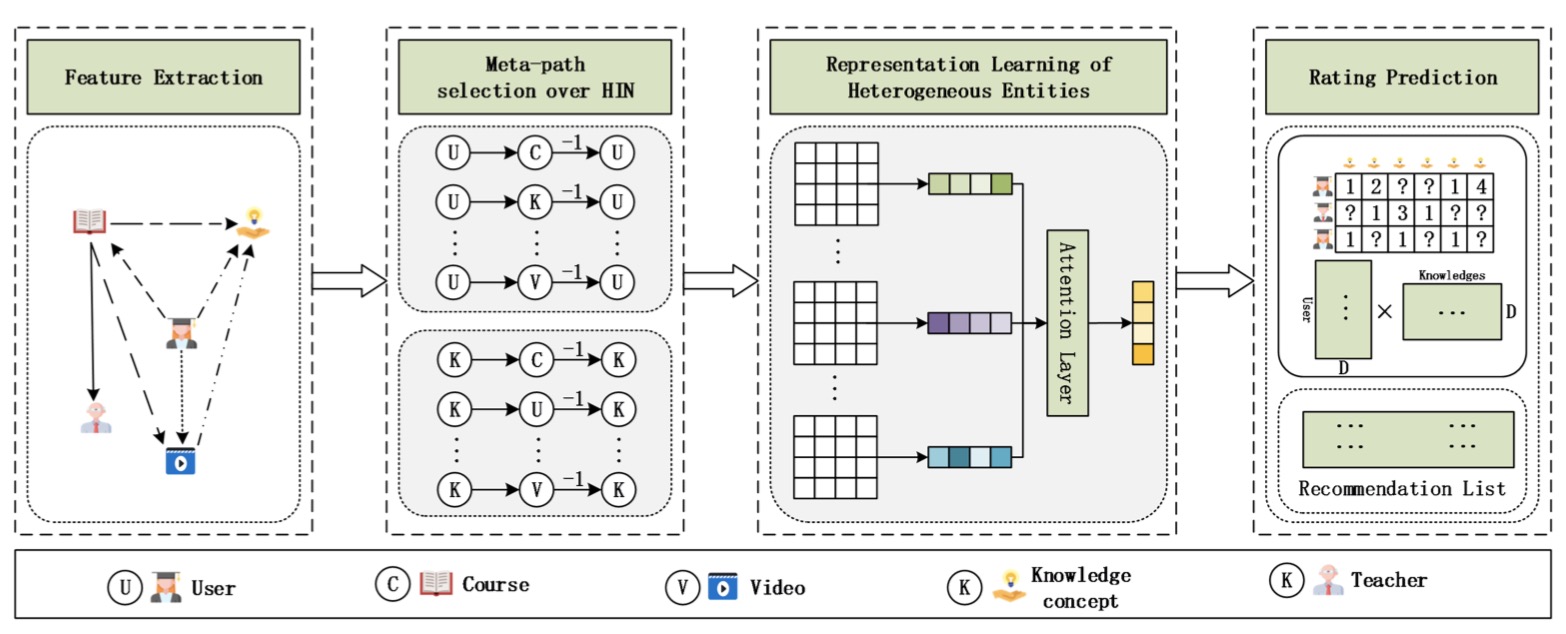
Massive open online courses (MOOCs) are becoming a modish way for education, which provides a large-scale and open-access learning opportunity for students to grasp the knowledge. To attract students’ interest, the recommendation system is applied by MOOCs providers to recommend courses to students. However, as a course usually consists of a number of video lectures, with each one covering some specific knowledge concepts, directly recommending courses overlook students’ interest to some specific knowledge concepts. To fill this gap, in this paper, we study the problem of knowledge concept recommendation. We propose an end-to-end graph neural network based approach called Attentional Heterogeneous Graph Convolutional Deep Knowledge Recommender (ACKRec) for knowledge concept recommendation in MOOCs. A series of experiments are conducted, demonstrating the effectiveness of ACKRec across multiple popular metrics compared with state-of-the-art baseline methods. The promising results show that the proposed ACKRec is able to effectively recommend knowledge concepts to students pursuing online learning in MOOCs.
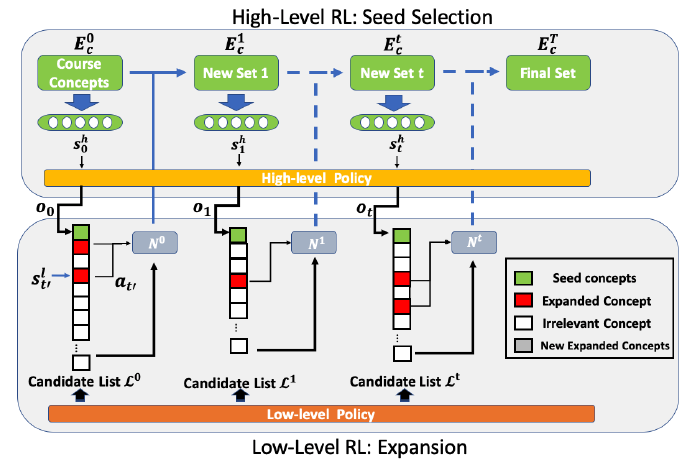
Within the prosperity of Massive Open Online Courses (MOOCs), the education applications that automatically provide extracurricular knowledge for MOOC users have become rising research topics. However, MOOC courses’ diversity and rapid updates make it more challenging to find suitable new knowledge for students. In this paper, we present ExpanRL, an end-to-end hierarchical reinforcement learning (HRL) model for concept expansion in MOOCs. Employing a two-level HRL mechanism of seed selection and concept expansion, ExpanRL is more feasible to adjust the expansion strategy to find new concepts based on the students’ feedback on expansion results. Our experiments on nine novel datasets from real MOOCs show that ExpanRL achieves significant improvements over existing methods and maintain competitive performance under different settings.
2019

As Massive Open Online Courses (MOOCs) become increasingly popular, it is promising to automatically provide extracurricular knowledge for MOOC users. Suffering from semantic drifts and lack of knowledge guidance, existing methods can not effectively expand course concepts in complex MOOC environments. In this paper, we first build a novel boundary during searching for new concepts via external knowledge base and then utilize heterogeneous features to verify the highquality results. In addition, to involve human efforts in our model, we design an interactive optimization mechanism based on a game. Our experiments on the four datasets from Coursera and XuetangX show that the proposed method achieves significant improvements(+ 0.19 by MAP) over existing methods. The source code and datasets have been published.
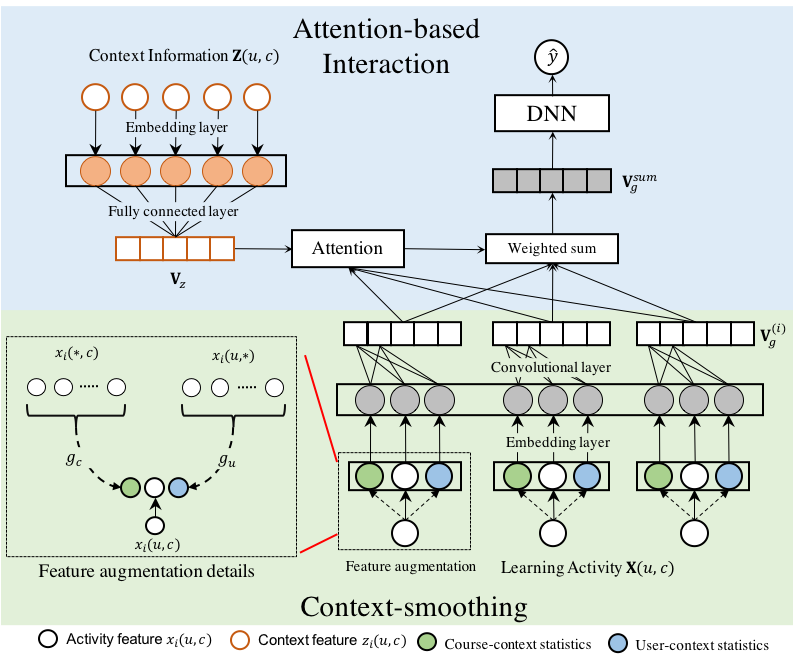
Massive open online courses (MOOCs) have developed rapidly in recent years, and have attracted millions of online users. However, a central challenge is the extremely high dropout rate — recent reports show that the completion rate in MOOCs is below 5% (Onah, Sinclair, and Boyatt 2014; Kizilcec, Piech, and Schneider 2013; Seaton et al. 2014). What are the major factors that cause the users to drop out? What are the major motivations for the users to study in MOOCs? In this paper, employing a dataset from XuetangX, one of the largest MOOCs in China, we conduct a systematical study for the dropout problem in MOOCs. We found that the users’ learning behavior can be clustered into several distinct categories. Our statistics also reveal high correlation between dropouts of different courses and strong influence between friends’ dropout behaviors. Based on the gained insights, we propose a Context-aware Feature Interaction Network (CFIN) to model and to predict users’ dropout behavior. CFIN utilizes context-smoothing technique to smooth feature values with different context, and use attention mechanism to combine user and course information into the modeling framework. Experiments on two large datasets show that the proposed method achieves better performance than several state-of-the-art methods. The proposed method model has been deployed on a real system to help improve user retention.
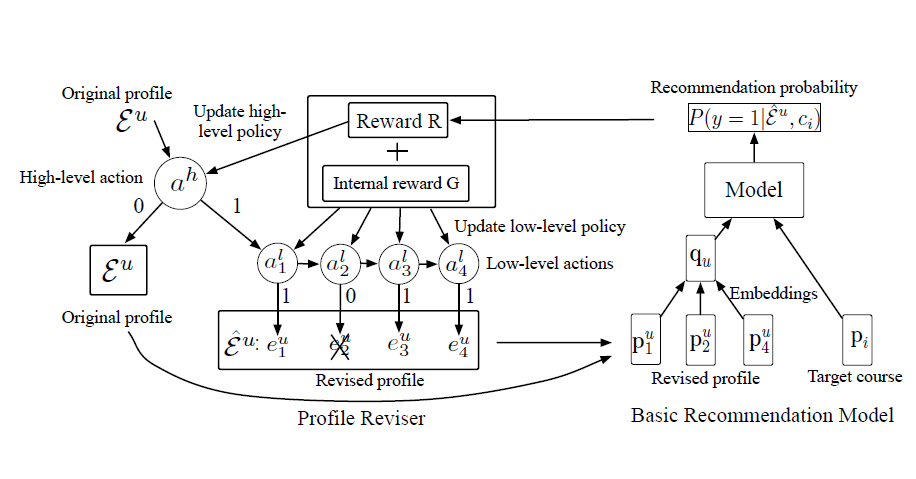
The proliferation of massive open online courses (MOOCs) demands an effective way of personalized course recommendation. The recent attention-based recommendation models can distinguish the effects of different historical courses when recommending different target courses. However, when a user has interests in many different courses, the attention mechanism will perform poorly as the effects of the contributing courses are diluted by diverse historical courses. To address such a challenge, we propose a hierarchical reinforcement learning algorithm to revise the user profiles and tune the course recommendation model on the revised profiles.
Systematically, we evaluate the proposed model on a real dataset consisting of 1,302 courses, 82,535 users and 458,454 user enrolled behaviors, which were collected from XuetangX—one of the largest MOOCs in China. Experimental results show that the proposed model significantly outper forms the state-of-the-art recommendation models (improving 5.02% to 18.95% in terms of HR@10).
2018

Implicit feedback, such as user clicks, although abundant in online information service systems, does not provide substantial evidence on users' evaluation of system's output. Such incomplete supervision inevitably misleads model estimation, especially in a bandit learning setting where the feedback is acquired on the fly. In this work, we study a contextual bandit problem with implicit feedback by modeling the feedback as a composition of user result examination and relevance judgment. Since users' examination behavior is unobserved, we introduce latent variables to model it. We perform Thompson sampling on top of variational Bayesian inference for arm selection and model update. Rigorous upper regret bound analysis of the proposed algorithm proves its feasibility of learning from implicit feedback; and extensive empirical evaluations on click logs collected from a major MOOC platform further demonstrate its learning effectiveness in practice.
2017
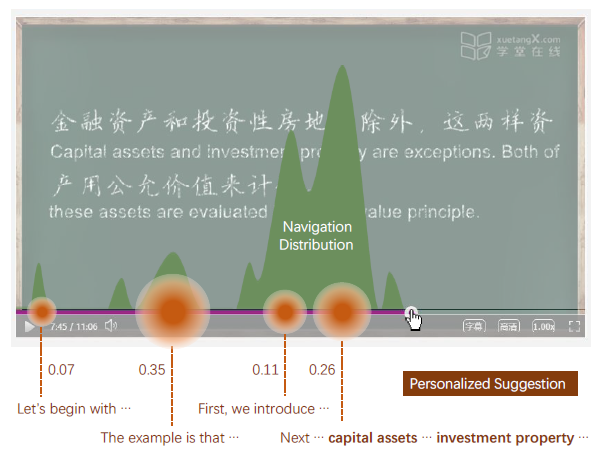
Statistics show that, on average, each user of Massive Open Online Courses (MOOCs) uses "jump-back" to navigate a course video for 2.6 times. By taking a closer look at the navigation data, we found that more than half of the jump-backs are due to the "bad" positions of the previous jump-backs. In this work, employing one of the largest Chinese MOOCs, XuetangX.com, as the source for our research, we study the extent to which we can develop a methodology to understand the user intention and help the user alleviate this problem by suggesting the best position for a jump-back. We demonstrate that it is possible to accurately predict 90% of users' jump-back intentions in the real online system. Moreover, our study reveals several interesting patterns, e.g., students in nonscience courses tend to jump back from the first half of the course video, and students in science courses tend to replay for longer time.

Massive Open Online Courses (MOOCs), offering a new way to study online, are revolutionizing education. One challenging issue in MOOCs is how to design effective and fine-grained course concepts such that students with different backgrounds can grasp the essence of the course. In this paper, we conduct a systematic investigation of the problem of course concept extraction for MOOCs. We propose to learn latent representations for candidate concepts via an embedding-based method. Moreover, we develop a graph-based propagation algorithm to rank the candidate concepts based on the learned representations. We evaluate the proposed method using different courses from XuetangX and Coursera. Experimental results show that our method significantly outperforms all the alternative methods (+0.013-0.318 in terms of Rprecision; p << 0.01, t-test).
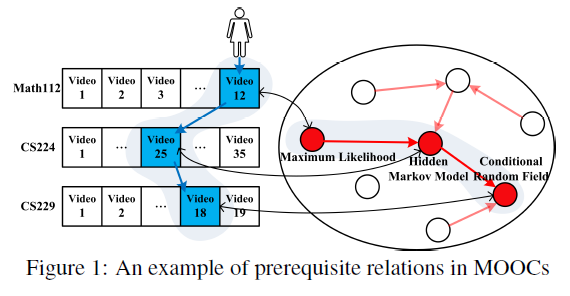
What prerequisite knowledge should students achieve a level of mastery before moving forward to learn subsequent coursewares? We study the extent to which the prerequisite relation between knowledge concepts in Massive Open Online Courses (MOOCs) can be inferred automatically. In particular, what kinds of information can be leveraged to uncover the potential prerequisite relation between knowledge concepts. We first propose a representation learning-based method for learning latent representations of course concepts, and then investigate how different features capture the prerequisite relations between concepts. Our experiments on three datasets form Coursera show that the proposed method achieves significant improvements (+5.9-48.0% by F1-score) comparing with existing methods.
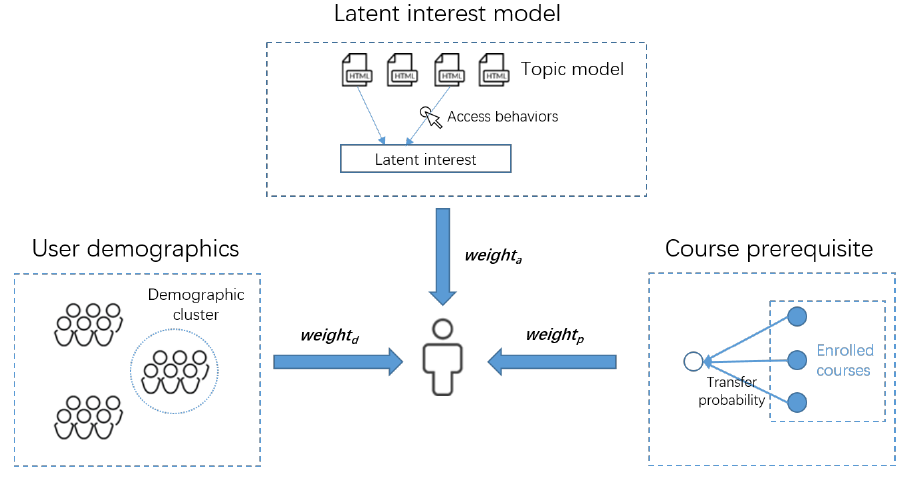
Recommending courses to online students is a fundamental and also challenging issue in MOOCs. Not exactly like recommendation in traditional online systems, students who enrolled the same course may have very different purposes and with very different backgrounds. For example, one may want to study "data mining" after studying the course of "big data analytics" because the former is a prerequisite course of the latter, while some other may choose "data mining" simply because of curiosity.
Employing the complete data from XuetangX, one of the largest MOOCs in China, we conduct a systematic investigation on the problem of student behavior modeling for course recommendation. We design a content-aware algorithm framework using content based users' access behaviors to extract user-specific latent information to represent students' interest profile. We also leverage the demographics and course prerequisite relation to better reveal users' potential choice. Finally, we develop a course recommendation algorithm based on the user interest, demographic profiles and course prerequisite relation using collaborative filtering strategy. Experiment results demonstrate that the proposed algorithm performs much better than several baselines (over 2X by MRR). We have deployed the recommendation algorithm onto the platform XuetangX as a new feature, which significantly helps improve the course recommendation performance (+24.6% by click rate) comparing with the recommendation strategy previously used in the system.
2016
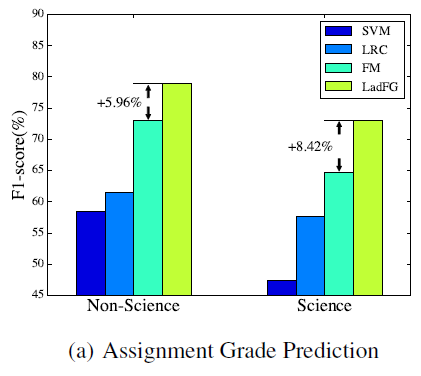
Massive Open Online Courses (MOOCs), which collect complete records of all student interactions in an online learning environment, offer us an unprecedented opportunity to analyze students' learning behavior at a very fine granularity than ever before.
Using dataset from xuetangX, one of the largest MOOCs from China, we analyze key factors that influence students' engagement in MOOCs and study to what extent we could infer a student's learning effectiveness. We observe significant behavioral heterogeneity in students' course selection as well as their learning patterns. For example, students who exert higher effort and ask more questions are not necessarily more likely to get certificates. Additionally, the probability that a student obtains the course certificate increases dramatically (3x higher) when she has one or more "certificate friends".
Moreover, we develop a unified model to predict students' learning effectiveness, by incorporating user demographics, forum activities, and learning behavior. We demonstrate that the proposed model significantly outperforms (+2.03-9.03% by F1-score) several alternative methods in predicting students' performance on assignments and course certificates. The model is flexible and can be applied to various settings. For example, we are deploying a new feature into xuetangX to help teachers dynamically optimize the teaching process.
invited talks


